

استارتاپ Sarvam با معرفی مدل های هوش مصنوعی متن باز جدید، به دنبال بومی سازی فناوری های زبانی در هند و رقابت با غول های جهانی از طریق کاهش هزینه های پردازشی است.
آزمایشگاه هوش مصنوعی هندی Sarvam روز سه شنبه از نسل جدیدی از مدل های زبانی بزرگ رونمایی کرد. این شرکت روی مدل های هوش مصنوعی متن باز کوچیک و کارآمد حساب باز کرده تا بتونه سهمی از بازار رو از رقبای بزرگ آمریکایی و چینی خودش که سیستم های گرون تری دارن، بگیره.
این رونمایی که در نشست تاثیر هوش مصنوعی هند در دهلی نو اعلام شد، در راستای تلاش های هند برای کاهش وابستگی به پلتفرم های خارجی و بومی سازی مدل ها برای زبان ها و کاربردهای محلی انجام شده و Sarvam در این مسیر با ارائه مدل های هوش مصنوعی متن باز پیشرو است.
Sarvam گفته که سری جدید شامل مدل های 30 میلیاردی و 105 میلیارد پارامتری، یک مدل تبدیل متن به گفتار، یک مدل تبدیل گفتار به متن و یک مدل بینایی برای تحلیل اسناد می شه. این مدل ها ارتقای خیلی بزرگی نسبت به مدل 2 میلیارد پارامتری Sarvam 1 هستن که در مهر 1403 عرضه شده بود.
نوآوری های Sarvam در مدل های هوش مصنوعی متن باز
طبق گفته ی Sarvam، مدل های 30 و 105 میلیارد پارامتری از معماری «ترکیب متخصصان» (mixture-of-experts) استفاده می کنن که در هر لحظه فقط بخشی از کل پارامترها رو فعال می کنه و این کار هزینه های پردازشی رو به شدت کاهش می ده. این رویکرد به توسعه مدل های هوش مصنوعی متن باز کمک می کند تا کارآمدتر باشند. مدل 30B از یک پنجره ی محتوای 32,000 توکنی برای مکالمات همزمان استفاده می کنه، در حالی که مدل بزرگتر یک پنجره ی 128,000 توکنی برای کارهای پیچیده تر و چند مرحله ای داره.
توی تصویر پایین می تونید ببینید که چطور مدل های جدید این شرکت در کنار بقیه فناوری های روز دنیا قرار می گیرن.
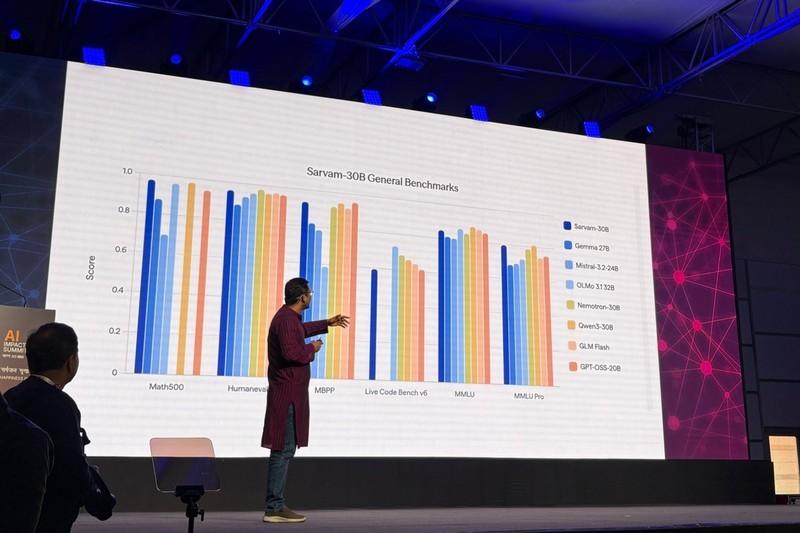
مدل 30B شرکت Sarvam در کنار مدل هایی مثل Gemma 27B گوگل و GPT-OSS-20B شرکت OpenAI قرار می گیره
این نمودار نشون می ده که مدل های بومی چقدر می تونن در مقابل رقبای بین المللی قدرتمند ظاهر بشن.
Sarvam اعلام کرد که این مدل های جدید هوش مصنوعی از صفر آموزش دیدن و بر پایه ی مدل های هوش مصنوعی متن باز موجود بهینه (Fine-tune) نشدن. مدل 30B با حدود 16 تریلیون توکن متنی آموزش دیده، در حالی که مدل 105B با تریلیون ها توکن از چندین زبان هندی آموزش داده شده.
این استارتاپ گفت که این مدل ها برای پشتیبانی از برنامه های همزمان، از جمله دستیارهای صوتی و سیستم های چت به زبان های هندی طراحی شدن.
برای اینکه مقیاس مدل های بزرگتر رو بهتر درک کنید، نگاهی به تصویر زیر بندازید.
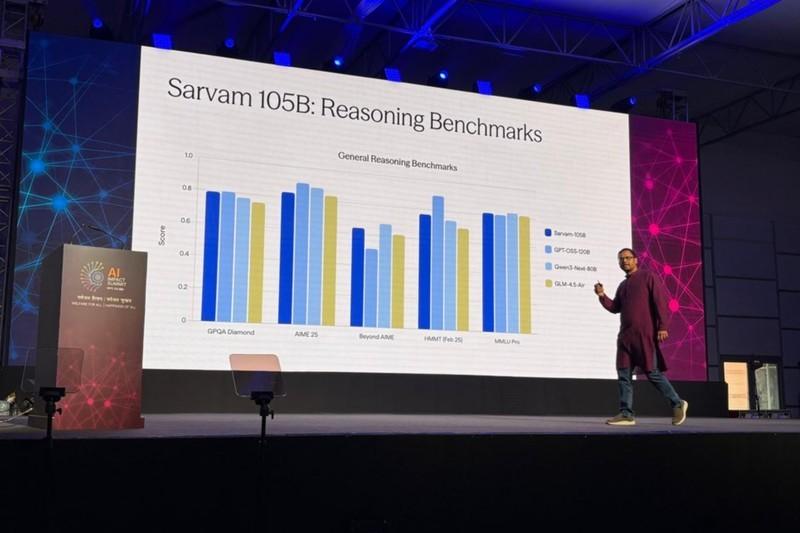
گفته می شه مدل 105B شرکت Sarvam رقیبی برای GPT-OSS-120B شرکت OpenAI و Qwen-3-Next-80B شرکت علی بابا خواهد بود
رقابت در این سطح نشون دهنده عزم جدی هند برای استفاده از کلان داده ها و زیرساخت های پیشرفته ست.
این استارتاپ گفت که این مدل ها با استفاده از منابع پردازشی ارائه شده تحت ماموریت IndiaAI (که توسط دولت هند حمایت می شه)، با پشتیبانی زیرساختی مرکز داده Yotta و حمایت فنی برای تقویت انویدیا در هوش مصنوعی با فناوری گروک آموزش دیدن.
رویکرد Sarvam به توسعه مدل های هوش مصنوعی متن باز
مدیران Sarvam گفتن که این شرکت قصد داره رویکردی حساب شده برای گسترش مدل هاش داشته باشه و به جای تمرکز صرف روی اندازه، روی کاربردهای واقعی تمرکز کنه و بدین ترتیب جایگاه خود را در میان مدل های هوش مصنوعی متن باز تثبیت کند.
«ما می خوایم در نحوه ی مقیاس بندی مدل ها هوشمندانه عمل کنیم.» پراتیوش کومار، هم بنیان گذار Sarvam در این مراسم گفت: «نمی خوایم بی هدف اون ها رو بزرگ کنیم. می خوایم کارهایی رو که واقعا در مقیاس بالا اهمیت دارن درک کنیم و برای اون ها راه حل بسازیم.»
Sarvam اعلام کرد که قصد داره مدل های 30B و 105B رو به عنوان مدل های هوش مصنوعی متن باز در دسترس عموم قرار بده، هرچند مشخص نکرد که آیا داده های آموزشی یا کد کامل آموزش هم عمومی می شن یا نه.
این شرکت همچنین برنامه هاش رو برای ساخت سیستم های هوش مصنوعی تخصصی، از جمله مدل های هوش مصنوعی متن باز متمرکز بر برنامه نویسی و ابزارهای سازمانی تحت محصولی به نام Sarvam for Work و یک پلتفرم عامل هوش مصنوعی مکالمه ای به اسم Samvaad ارائه داد.
شرکت Sarvam که در سال 1402 تاسیس شده، بیش از 50 میلیون دلار سرمایه جذب کرده و شرکت هایی مثل Lightspeed Venture Partners، Khosla Ventures و Peak XV Partners (سکویا کاپیتال هند سابق) از سرمایه گذاران اون هستن.
رونمایی از این مدل های جدید نشون دهنده حرکت به سمت سیستم های بهینه و تخصصی به جای مدل های خیلی بزرگ و پرهزینه ست. استارتاپ Sarvam با تمرکز روی نیازهای بومی و استفاده از معماری های جدید، مسیر رو برای توسعه کاربردی تر هوش مصنوعی در هند هموار کرده.
Indian AI lab Sarvam’s new models are a major bet on the viability of open-source AI



